
Tone shift, the technique of generating singing voices at a target pitch while using desired vocal techniques from other registers, is essential in singing voice synthesis (SVS). To achieve this, SVS systems often rely on pitch-controllable neural vocoders, whose performance remains limited by three factors: complex input feature requirements that hinder SVS integration, sub-optimal pitch controllability, and limited synthesis fidelity. This paper proposes NSF-Pupu-Vocoder to address these issues. In contrast to previous models that rely on complex preprocessing and training schemes, our model uses highly compatible mel-spectrograms and pitch contours as inputs, and achieves feature decoupling simply by injecting a pitch excitation into the exact layer whose temporal resolution can accommodate the pitch. Experiments show that our model achieves competitive pitch controllability and superior synthesis fidelity, while preserving the original singer's timbre during pitch manipulation.
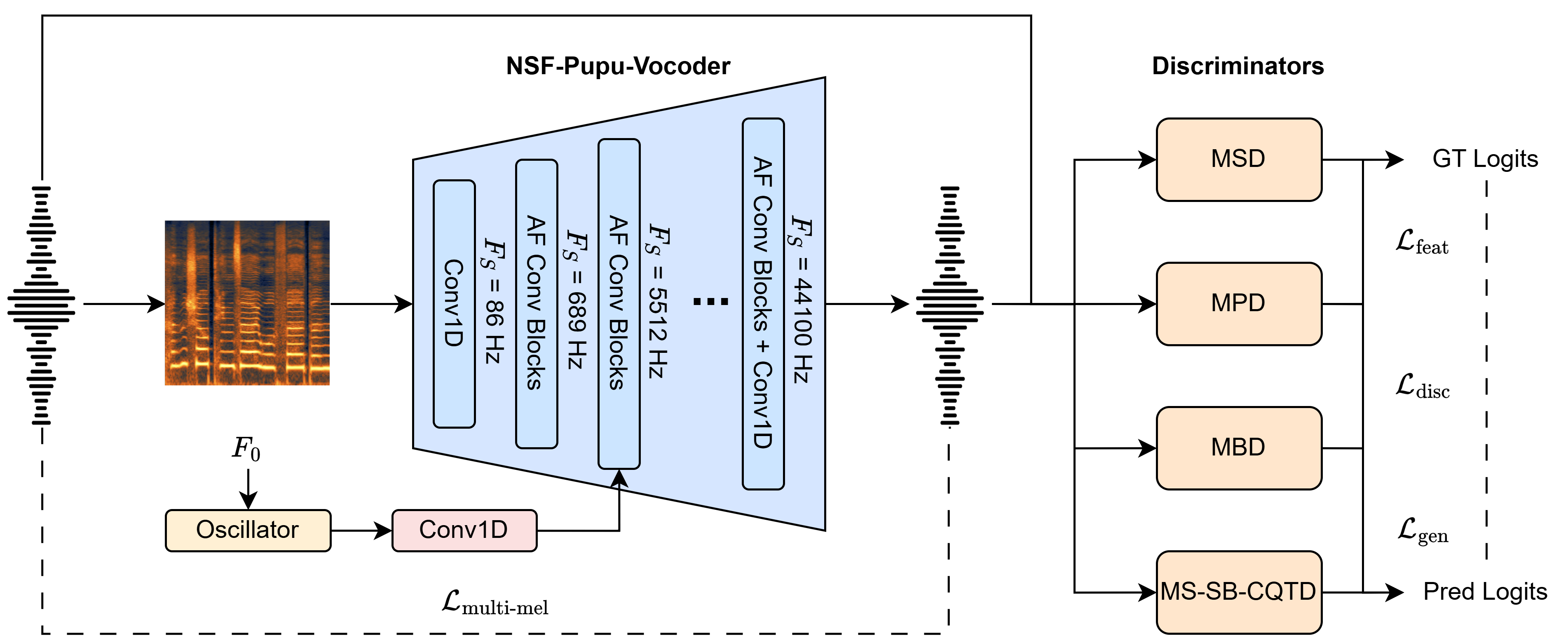
NSF-Pupu-Vocoder is a lightweight and high-fidelity pitch-controllable neural vocoder that achieves precise pitch controllability and superior synthesis quality using resolution-specific feature injection, as illustrated in the figure above. It avoids the complex DSP preprocessing and intricate adversarial and cycle-consistency training by injecting a pitch excitation condition only at the exact network layer whose temporal resolution is high enough to accommodate pitch, creating a strict information bottleneck that forces the model to ignore entangled pitch information in the input mel-spectrogram. To illustrate its effectiveness, we conduct experiments in both copy-synthesis and global pitch-manipulation scenarios ranging from -12 to +12 semitones.
We conduct experiments in copy-synthesis and global pitch-manipulation ranging from -12 to +12 semitones to illustrate the effectiveness of our proposed model. We use HiFi-GAN, BigVGAN, Vocos, and Pupu-Vocoder as the Neural Vocoder baselines for copy-synthesis. We use WORLD, and TD-PSOLA, as the DSP-based pitch manipulation baselines. We use SiFi-GAN, PC-NSF, PeriodCodec, and Neurodyne as the DL-based pitch manipulation baselines.
| Manipulation Scales |
GT |
HiFi-GAN (NIPS 2020) |
BigVGAN (ICLR 2023) |
Vocos (ICLR 2024) |
Pupu-Vocoder |
WORLD (IEICE TIS 2016) |
TD-PSOLA (Eurospeech) |
SiFi-GAN (ICASSP 2023) |
PC-NSF (TASLP 2023) |
PeriodCodec (Interspeech 2025) |
Neurodyne (Interspeech 2025) |
NSF-Pupu-Vocoder (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -12 | / | / | / | / | / | |||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| -6 | / | / | / | / | / | |||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| -3 | / | / | / | / | / | |||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| 0 | ||||||||||||
| 3 | / | / | / | / | / | |||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| 6 | / | / | / | / | / | |||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| 12 | / | / | / | / | / | |||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / | ||||||||
| / | / | / | / | / |